

The Path to Microservices CI/CD Nirvana
What is CI/CD Nirvana?
Stackchat is a complicated platform from a DevOps perspective. It contains dynamically provisioned infrastructure, multiple AWS accounts per environment, dozens of Lambda-powered and Fargate-powered APIs and many other idiosyncrasies. For us, microservices CI/CD nirvana looks like the following:
- The power to scale infrastructure up and down quickly, easily and without downtime.
- The ability to easily spin-up new platform instances for feature branches, partner testing and new geographic regions.
- Inexpensive infrastructure, utilizing automated cost saving mechanisms such as spot instances and scheduled cluster shutdowns and resizing.
- Fully-automated, platform-wide code deployments completed in under an hour.
- Automation of all repetitive ops processes such as certificate renewal, backups, version cleanups, security hardening and git repository maintenance.
- Empowered developers creating and publishing new API services without involving the DevOps team.
There is plenty more exciting work planned over the next 12 months and the journey is far from over, but we are really happy with the current setup and feel that it's a good time to share some of our learnings.
Why we chose Buildkite + Ansible + Cloudformation to deploy our Infrastructure
Over the course of 24 months, we have built a global chat platform, with a focus on security, scalability and auditability.
We were able to build our platform and scale it out with a single-person DevOps team, avoiding many of the common pitfalls, largely thanks to a new breed of excellent DevOps tooling that favours simplicity over features, and by ensuring that we strictly adhere to good engineering principals.
In this post I will give a description of those engineering principals and will lay out the strengths and weaknesses of the tools that we chose.
I will also give some example code and screenshots at the end, with deep-dives on specific tasks and pipelines to follow in subsequent posts.
The engineering principals we live by
DRY
"Don't Repeat Yourself" or the DRY principle is stated as, "Every piece of knowledge or logic must have a single, unambiguous representation within a system."
Not only does DRY make code more efficient and readable, but it also encourages coders to observe other best practice conventions. For example, DRY motivates us to create reusable modules or templates which can be used and improved by other members of the team. The practice also encourages us to look for the most elegant solutions to any problems we encounter.
KISS
“Keep it simple, stupid” is thought to have been coined by the late Kelly Johnson, who was the lead engineer at the Lockheed Skunk Works, a place responsible for the S-71 Blackbird spy plane amongst many other notable achievements. Kelly explained the idea to others with a simple story. He told the designers at Lockheed that whatever they made had to be something that could be repaired by a man in a field with some basic mechanic’s training and simple tools.
To us, this translates directly to infrastructure design. All tooling should be easily maintained and modified by junior engineers with miminal assistance.
This can also be seen as a counterpoint to dogmatically adhering to DRY. Before creating a new module or script, We need to ask ourselves if it provides enough advantages to justify the increased complexity.
YAGNI
Yagni stands for "You Aren't Gonna Need It". The Yagni principle prevents over-engineering by limiting the development of speculative future software features because, more likely than not, "you aren't gonna need it".
Designing for future hypothetical use cases (especially related to performance optimization) is a common pitfall in DevOps which leads to time-wasting and bloated code bases that are hard to maintain. Remember, features are easy to add, but hard to remove so only build what you need right now.
Principle Of Least Astonishment
This principle means that your code should be intuitive and obvious, and not surprise another engineer when reviewing your code. If you hear your team mate muttering "what the f*!$%?" under their breath after you send them a PR, you are most likely in breach of this principal.
For variables, modules, roles, etc. your naming should always reflect the component's purpose, striking a balance between wordy and ambiguous, and the logic you create should be easy to follow.
Don't Over-Engineer
This one is especially close to our hearts and encapsulates most of the previous principals.
The pernicious effects of over-engineering can cripple an engineering team as a business scales, especially if it happens quickly.
Keeping your infrastructure code small and modular and not reinventing functionality already present in your chosen tooling (RTM before writing a new module), will allow your infrastructure to scale exponentially without requiring your team to.
Some common over-engineering crimes and their outcomes:
Abstraction
The temptation to wrap wrappers in wrapped wrappers is often too strong to resist for engineers in our industry. Abstraction is essential and exists at every level of an application, however it should be used sparingly to avoid the compounding costs involved.
It may save you some future typing to use the latest so-hot-right-now-on-hacker-news tool in order to avoid the manual creation of a new module. However when it mysteriously breaks your integration pipeline six months down the track after a seemingly unrelated package update, and all traces of the tool and its author have dissappeared off the internet, you may regret having added so many layers of indirection and abstraction to your stack.
State
Avoid state when you can design a system without it. Like abstraction, state is everywhere and is a core building block of applications, but like abstraction, too much will lead to increased complexity and will add to your accumulative technical debt and maintenance burden.
Microservices vs Monolith
Before we get into the tooling we chose, it's worth briefly addressing our decision to go with a microservice (vs. a monolith) architecture. Both approaches have strengths and weaknesses, the finer points of which we will discuss in a future post. For the sake of brevity here, I'll just say that the added complexity of a microservices architecture was worth it for this project and it has given us the agility needed to quickly pivot and scale out the platform in a way that would be hard to imagine using a monolith without a significantly larger team.
If you do decide to adopt a microservices architecture, this post will hopefully give you an idea of the type of investment you can expect to make in your CI/CD processes in order to successfully build, scale and maintain your infrastructure.
Buildkite, Ansible, and Cloudformation
In this section I'll briefly describe our chosen tooling and will then deep dive into the strengths and weaknesses of each one, providing comparisons to other popular tooling.
As with all tooling assessments, the strengths and weaknesses I've outlined are highly subjective and may not ring true with you, but hopefully there is value in sharing our decision making process and subsequent outcomes.
Buildkite
Buildkite is a CI and build automation tool that combines the power of your own build servers with the convenience of a managed, centralized web UI. Buildkite allows us to automate complicated delivery pipelines and it gives us crazy levels of flexibility around custom checkout logic and dynamically building pipelines as part of a build.
Ansible
Ansible is an IT automation tool. It can configure systems, deploy software, and orchestrate more advanced DevOps tasks such as continuous deployments or zero downtime rolling updates.
Ansible’s goals are foremost those of simplicity and maximum ease of use. This approach has resulted in it recently overtaking Chef to become the most popular configuration management tool in the world.
Cloudformation
AWS Cloudformation allows us to use programming languages or simple config files to model and automatically provision all the AWS resources needed for Stackchat across all our supported regions and accounts.
This gives us a single source of truth for our infrastructure that can live in an API's code base next to the application code, empowering Developers to make infrastructure changes alongside their regular commits.
Buildkite
In a crowded market Buildkite distinguishes itself by being simple, fast and intelligently designed.
Strengths
Simple
Like Ansible, Buildkite pipelines are configured with YAML. A common configuration language is a big plus for us.
Compared to venerable stallwarts of CI/CD such as Jenkins and Bamboo, Buildkite has a fraction of the features and plugins. For us this is actually a huge plus, as we like to do everything with Ansible and use the CI solely to bootstrap it. This lack of bloat makes it a joy to use in this fashion.
Intelligently Designed
While Buildkite may be light on features, it isn't missing anything we need. This is no mean feat and is testament to a company with great engineering that listens to its customers.
They may not have a plugin to integrate with HP Operations Orchestration, or a Skype Notifier, or 1714 other plugins like Jenkins. They do however provide, via github, an excellent Elastic CI Stack for AWS codebase that allows you to easily implement an autoscaling fleet of build agents running on AWS Spot Instances, that can scale all the way down to zero when not in use. This gives us infinite horizontal scale for large deploys, overnight maintenance, and integration and load testing, at a very cheap cost, with very little engineering investment on our end.
Hosted
As a Serverless company, hosted is essential for us and Buildkite's speed and uptime has been flawless.
Open Source
Buildkite is also open source, which aligns with our company values and future goals. They host all of their code publicly on their github, even their own website!
Support
Buildkite support desk is top notch.
There are no levels to work your way through to get to someone who can help and no attempts to defer blame. You hit a knowledgeable engineer straight away and more often then not get the solution first time. If there is no immediate solutions they go out of their way to help with workarounds. If it's a bug in their system they tell you straight up and they fix it.
They also provide a weekly community summary via email containing announcements and features, as well as help requests from the forum. It has been surprisingly helpful to see other companies issues and how they solved them.
Company Culture
While not a technical requirement, it's nice to work with companies who's values align with yours. Their values from their website:
- Transparency
- Empathy
- Quality
- Collaboration
- Diversity
- Sustainable Growth
- Independence
Weaknesses
Lack of Features and Plugins
While this was a plus for us, people who prefer batteries included solutions should look elsewhere.
Example Buildkite pipeline
This simple pipeline is the standard one we use for our Typescript Node APIs. This is triggered on git commits to each individual microservice repository.
1---2steps:3 - label: ":ansible: Run stack_node.yml playbook"4 command:5 cd environment-automation/ansible/ &&6 ansible-playbook7 -e product=io8 stack_node.yml9
Our shared automation and configuration code lives in the environment-automation repository, which is accessed as a git submodule in all our other repositories. This allows us to test changes to our automation code in a specific branch/environment of a microservice without affecting others. These changes can then either be merged into integration via a pull request, or discarded.
Our pipelines simply bootstrap Ansible with a single product fact, which is our classifier for the different products we build. The rest of the facts, such as the AWS Account ID, Environment and the Cloudformation Stack Name are then generated by Ansible, based on the git branch and pipeline name.
This is demonstrated in the image below. The build was triggered by a pull request into our integration branch of our IO User API. Based on the product io, the branch integration and the user-api repo name, Ansible generates the IoIntegrationUserApi stack name and creates/updates that stack in the dev AWS account where our Integration environment lives.
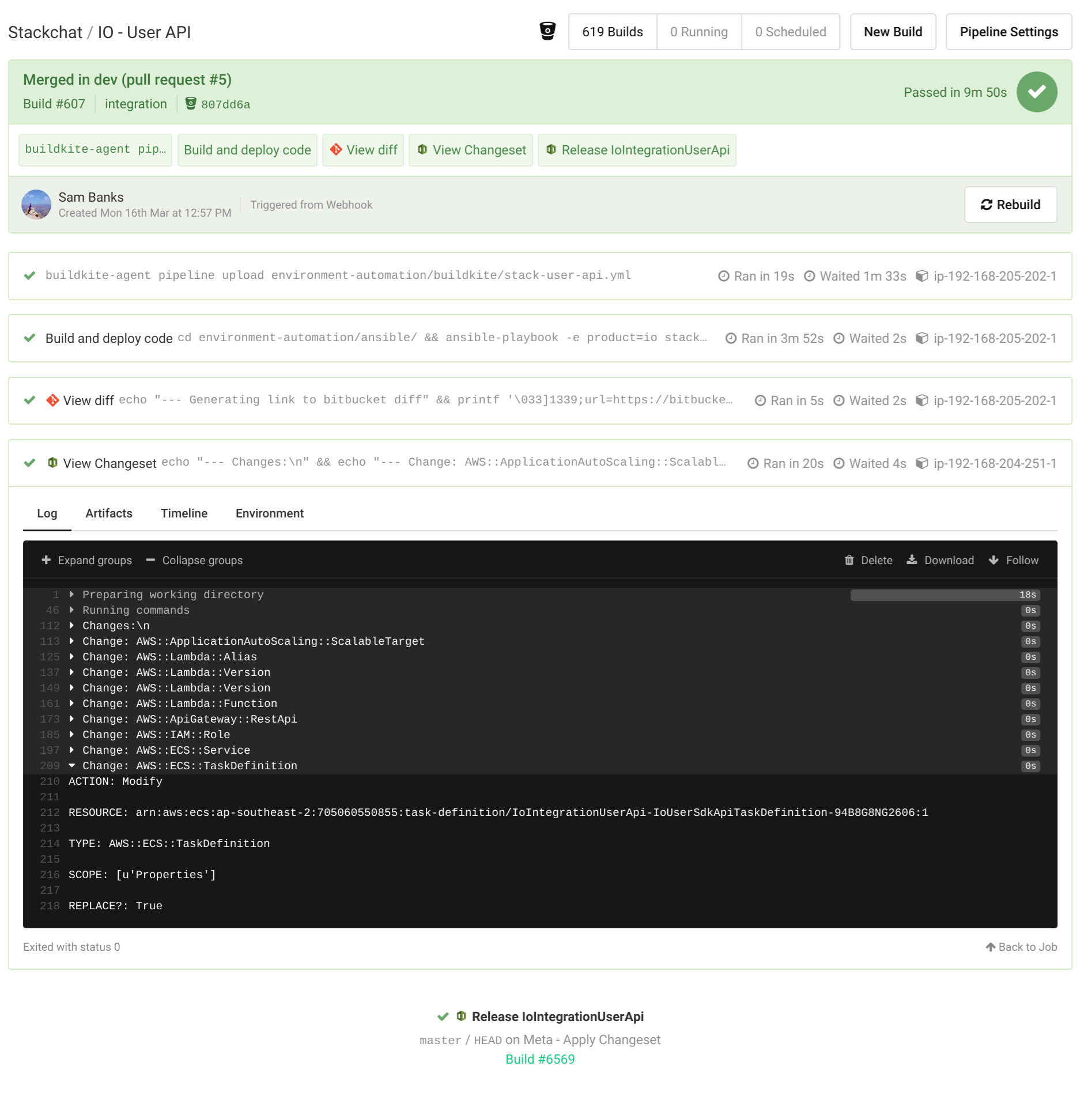 Buildkite Screenshot
Buildkite ScreenshotAnsible

The Swiss Army Knife of Continuous Integration, Continuous Deployment and Configuration Management.
Strengths
Simple to learn
Ansible playbooks are imperative, rather than declarative. Most automation and infrastructure management tools work by declaring a state of configuration. With Ansible you define a series of steps that are executed in order. This makes Ansible much easier to learn for engineers coming from scripting backgrounds.
Writing Ansible is similar in many ways to scripting, supporting popular imperative programming constructs such as conditionals, loops, and dynamic includes. Ansible modules are written in YAML, which is extremely popular, being one of the easiest configuration languages to use.
Declarative Modules
While automation code written in Ansible is written in simple imperative playbooks and roles, the modules provided by Ansible work in a declarative fashion. This gives you the best of both worlds.
Agentless
Chef, Puppet, Saltstack and so on have a master and a client. They need to be installed and configured on both the master and the client. Ansible requires installation only on the master server. It communicates with the other nodes through SSH.
While this isn't a concern for us, since our infrastructure is serverless with Ansible running standalone (no master) on our build agents, it is worth mentioning.
Idempotent
When you write a playbook for configuring your nodes, Ansible first checks if the state defined by each step is different from the current state of the nodes and only makes changes if required. Therefore if a playbook is executed multiple times, it will still result in the same system state.
Batteries Included
Ansible comes out-of-the-box ready to use, with everything you need to manage the infrastructure, networks, operating systems and services that you are already using via the 3000+ included modules.
These modules make it incredibly easy to perform complex tasks across virtually any Public Cloud and Private Infrastructure running any Operating System and Software Stack.
Multi Purpose
Unlike single purpose orchestration tools like Terraform, Ansible supports orchestration and configuration management, as well as much more.
While one tool might do specific things better than another, applying the 80/20 rule and keeping your stack lean, at the expense of non-core functionality, pays huge dividends as your business scales.
Weaknesses
Speed
Ansible is slower than many other tools, possibly due to it's serial nature and it's "push" model. This gets worse at scale. This isn't much of a problem for us due to our masterless setup and the awesomeness of Buildkite, which we will get into soon.
Example Ansible playbook
This is the stack_node.yml Ansible playbook that was bootstrapped by Buildkite in the previous example.
1---2- hosts: all3 gather_facts: true4 roles:5 - add_groups6 - aws_sts_assume_role7 - get_facts8 - npm_token9 - node_test10 - role: node_build11 when: deploy == true12 - role: artifact_upload13 when: deploy == true14 - role: aws_cloudformation_deploy15 template: "{{bk_root}}/cloudformation_template.yml.j2"16 when: deploy == true17
Lines 5-9 trigger the roles that set up the environment, gather all the variables based on the git branch, then run all the tests defined within the microservice codebase. These roles are executed every time there is a push to any branch in the codebase.
Lines 10-16 contain conditional roles; which only run on deploy-enabled git branches (e.g dev, integration, etc.). These roles compile the code, upload it to s3, then deploy it to a Lambda function via Cloudformation.
The Cloudformation template for each microservice is collected by Ansible from the root of the git repository for that microservice. This allows us to use shared playbooks and pipelines and therefore add microservices to our stacks without our automation code sprawling.
Cloudformation

Amazon's infrastructure-as-code solution provides a feature-rich automation and deployment platform.
Strengths
Language Support
Cloudformation allows you to write templates in YAML or JSON. But if you would prefer to use a full fat programming language of your choice the recently released Cloud Development Kit allows you to define your application using TypeScript, Python, Java, and .NET.
Vendor Support
You can orchestrate infrastructure in AWS using external tooling such as Terraform, Salt, Puppet and even Ansible via modules. While this does work and is an approach preferred by many, it violates several of our engineering principals and can lead to significant problems:
Complexity
The level of abstraction that make tools like Terraform more attractive to many newcomers inevitably leads to sprawling codebases that are hard to maintain and even harder to uplift.
Many are also stateful, such as Terraform which uses a state file (why???), and require complex state modification when importing resources or resolving conflicts.
Features
Newly released Amazon products are immediately available in Cloudformation. When using external tooling you have to wait for someone to write (and hopefully test) a new module to support the product.
Stability
When you deploy a change via Cloudformation that requires a new resource, Amazon creates a new resource and waits until it is available and healthy before seamlessly replacing and deleting the old resources. If there are any issues a rollback is easy, as the old resources are kept until the cleanup stage of the deployment and it also results in reliably zero-downtime deploys. While some preference tools like Terraform for the speed of their in-place modifications, the ability to avoid downtime and roll back automatically is more important to us.
Extensibility
The recently released AWS Cloudformation Registry means you can now define third party resources in Cloudformation. For us being able to define our Datadog alerts in the Cloudformation template for the microservice that they are monitoring is a huge win.
Dependency Management
AWS Cloudformation automatically manages dependencies between your resources during stack management actions. You do not need to worry about specifying the order in which resource are created, updated, or deleted. Cloudformation determines the correct sequence of actions to use for each resource when performing stack operations.
This, along with the imperative nature of Ansible, means we get to completely avoid dependency management, which is a huge maintenance overhead in many other tools such as Puppet.
Weaknesses
Slow
Due to the deployment style of Cloudformation, which preferences zero-downtime and rollbacks over speed, it is slower than tools that do in-place updates.
(Mostly) Single Vendor
While they have recently introduced the Cloudformation Registry, this isn't for deploying to other clouds like Azure and GCP. For multi-cloud look elsewhere.
Example Cloudformation template
This is the cloudformation_template.yml.j2 that lives in the root of the user-api repository and is executed via the aws_cloudformation_deploy role in the Ansible playbook. Keeping infrastructure code next to application code makes our platform easy to reason about and maintain.
We prefer a combination of Ansible Inventory and the AWS SSM Parameter store over the Cloudformation Parameter Mappings you will see in many example templates on the web.
Ansible uses Jinja2 for it's templating including all the default filters as well as many excellent Ansible filters, adding lots of functionality, allowing us to simplify our templates. Before submitting the template to the Cloudformation SDK Ansible will evaluate the Jinja2 template and write it to cloudformation_template.yml after performing any transformations and replacing variable names (double curly braces {{var}}) with parameters from SSM or facts from Ansible.
Parameters pulled from SSM such as {{IoAppTableArn}} are scoped to the environment, which keeps environment permissions sandboxed and prevents cross-environment pollution.
This is one of our most complex templates; as this stack has multiple APIs in both Lambda, which is our default; and also Fargate, which we use for our IO product APIs that require more speed.
1#jinja2: trim_blocks: True, lstrip_blocks: True2---3AWSTemplateFormatVersion: '2010-09-09'4Transform: AWS::Serverless-2016-10-3156Resources:7 IoUserApi:8 Type: AWS::Serverless::Api9 Properties:10 StageName: Live11 MethodSettings:12 - HttpMethod: '*'13 ResourcePath: /*14 LoggingLevel: INFO15 DataTraceEnabled: true16 MetricsEnabled: true17 DefinitionBody:18 swagger: 2.019 info:20 title: {{stack_name}}21 x-amazon-apigateway-policy:22 Version: 2012-10-1723 Statement:24 - Effect: Allow25 Principal: '*'26 Action:27 - execute-api:Invoke28 Resource: execute-api:/*29 securityDefinitions:30 sigv4:31 type: apiKey32 name: Authorization33 in: header34 x-amazon-apigateway-authtype: awsSigv435 tenant-id-authorizer:36 type: apiKey37 name: Authorization38 in: header39 x-amazon-apigateway-authtype: custom40 x-amazon-apigateway-authorizer:41 authorizerResultTtlInSeconds: 30042 authorizerUri:43 !Sub arn:${AWS::Partition}:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/{{AuthorizerArn}}/invocations44 type: token45 paths:46 /admin/apps/{appId}/users:47 options:48 x-amazon-apigateway-integration:49 httpMethod: POST50 type: aws_proxy51 uri: !Sub arn:${AWS::Partition}:apigateway:{{cf_region}}:lambda:path/2015-03-31/functions/${IoUserAdminApiFn.Arn}/invocations52 x-amazon-apigateway-any-method:53 security:54 - tenant-id-authorizer: []55 x-amazon-apigateway-integration:56 httpMethod: POST57 type: aws_proxy58 uri: !Sub arn:${AWS::Partition}:apigateway:{{cf_region}}:lambda:path/2015-03-31/functions/${IoUserAdminApiFn.Arn}/invocations59 /admin/apps/{appId}/users/{proxy+}:60 options:61 x-amazon-apigateway-integration:62 httpMethod: POST63 type: aws_proxy64 uri: !Sub arn:${AWS::Partition}:apigateway:{{cf_region}}:lambda:path/2015-03-31/functions/${IoUserAdminApiFn.Arn}/invocations65 x-amazon-apigateway-any-method:66 security:67 - tenant-id-authorizer: []68 x-amazon-apigateway-integration:69 httpMethod: POST70 type: aws_proxy71 uri: !Sub arn:${AWS::Partition}:apigateway:{{cf_region}}:lambda:path/2015-03-31/functions/${IoUserAdminApiFn.Arn}/invocations72 /sdk/apps/{appId}/users/{proxy+}:73 options:74 parameters:75 - name: appId76 in: path77 required: true78 type: string79 - name: proxy80 in: path81 required: true82 type: string83 responses: {}84 x-amazon-apigateway-integration:85 uri: https://{{IoClusterServiceApiUrl}}/users/sdk/apps/{appId}/users/{proxy}86 responses:87 default:88 statusCode: 20089 requestParameters:90 integration.request.path.appId: method.request.path.appId91 integration.request.path.proxy: method.request.path.proxy92 passthroughBehavior: when_no_match93 httpMethod: ANY94 type: http_proxy95 x-amazon-apigateway-any-method:96 produces:97 - application/json98 parameters:99 - name: appId100 in: path101 required: true102 type: string103 - name: proxy104 in: path105 required: true106 type: string107 responses: {}108 security:109 - sigv4: []110 x-amazon-apigateway-integration:111 uri: https://{{IoClusterServiceApiUrl}}/users/sdk/apps/{appId}/users/{proxy}112 responses:113 default:114 statusCode: 200115 requestParameters:116 integration.request.path.appId: method.request.path.appId117 integration.request.path.proxy: method.request.path.proxy118 integration.request.header.x-cognito-identity-id: context.identity.cognitoIdentityId119 integration.request.header.x-cognito-identity-pool-id: context.identity.cognitoIdentityPoolId120 passthroughBehavior: when_no_match121 httpMethod: ANY122 type: http_proxy123124 IoUserApiBasePathMapping:125 Type: AWS::ApiGateway::BasePathMapping126 DependsOn: IoUserApiLiveStage127 Properties:128 BasePath: users129 DomainName: {{IoSharedApiGatewayUrl}}130 RestApiId: !Ref IoUserApi131 Stage: Live132133 IoUserAdminApiFnLambdaExecRole:134 Type: AWS::IAM::Role135 Properties:136 AssumeRolePolicyDocument:137 Version: 2012-10-17138 Statement:139 - Effect: Allow140 Action:141 - sts:AssumeRole142 Principal:143 Service:144 - lambda.amazonaws.com145 Path: /146 Policies:147 - PolicyName: AttachedPolicy148 PolicyDocument:149 Version: 2012-10-17150 Statement:151 - Effect: Allow152 Action: dynamodb:*153 Resource:154 - {{IoAppTableArn}}155 - {{IoAppTableArn}}/index/*156 - Effect: Allow157 Action:158 - ssm:GetParametersByPath159 - ssm:GetParameters160 - ssm:GetParameter161 Resource: !Sub arn:${AWS::Partition}:ssm:{{cf_region}}:{{cf_account}}:parameter/{{env}}/*162 - Effect: Allow163 Action: ssm:DescribeParameters164 Resource: '*'165 - Effect: Allow166 Resource: '*'167 Action:168 - xray:PutTelemetryRecords169 - xray:PutTraceSegments170 ManagedPolicyArns:171 - !Sub arn:${AWS::Partition}:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole172173 IoUserAdminApiFn:174 Type: AWS::Serverless::Function175 Properties:176 CodeUri: {{code_uri}}177 Role: !GetAtt IoUserAdminApiFnLambdaExecRole.Arn178 Runtime: nodejs10.x179 Handler: adminHandler/adminHandler.adminHandler180 Timeout: 300181 MemorySize: 1024182 AutoPublishAlias: live183184 InvokeIoUserAdminApiPermission:185 Type: AWS::Lambda::Permission186 Properties:187 Action: lambda:InvokeFunction188 FunctionName: !Ref IoUserAdminApiFn189 Principal: apigateway.amazonaws.com190191 IoUserSdkApiRole:192 Type: AWS::IAM::Role193 Properties:194 AssumeRolePolicyDocument:195 Version: 2012-10-17196 Statement:197 - Effect: Allow198 Action:199 - sts:AssumeRole200 Principal:201 Service:202 - ecs-tasks.amazonaws.com203 Path: /204 Policies:205 - PolicyName: AttachedPolicy206 PolicyDocument:207 Version: 2012-10-17208 Statement:209 - Effect: Allow210 Action: dynamodb:*211 Resource:212 - {{IoAppTableArn}}213 - {{IoAppTableArn}}/index/*214 - Effect: Allow215 Action:216 - xray:PutTraceSegments217 - xray:PutTelemetryRecords218 - ecr:*219 - sts:AssumeRole220 - iam:GetRole221 - iam:PassRole222 Resource: '*'223 - Effect: Deny224 Action:225 - logs:CreateLogStream226 - logs:PutLogEvents227 Resource: '*'228 - Effect: Allow229 Action:230 - ssm:GetParameterHistory231 - ssm:GetParametersByPath232 - ssm:GetParameters233 - ssm:GetParameter234 Resource: !Sub arn:${AWS::Partition}:ssm:{{cf_region}}:{{cf_account}}:parameter/{{env}}/*235 - Effect: Allow236 Action: ssm:DescribeParameters237 Resource: '*'238 - Effect: Allow239 Action: iot:Publish240 Resource:241 !Sub arn:${AWS::Partition}:iot:${AWS::Region}:${AWS::AccountId}:topic/live-chat/*242 ManagedPolicyArns:243 - !Sub arn:${AWS::Partition}:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole244 - !Sub arn:${AWS::Partition}:iam::aws:policy/service-role/AmazonEC2ContainerServiceAutoscaleRole245246 IoUserSdkApiTaskDefinition:247 Type: AWS::ECS::TaskDefinition248 Properties:249 Cpu: '{{ecs_cpu_multiplier*256}}'250 Memory: '{{ecs_mem_multiplier*512}}'251 NetworkMode: awsvpc252 RequiresCompatibilities:253 - {{ecs_launch_type}}254 ExecutionRoleArn: !GetAtt IoUserSdkApiRole.Arn255 TaskRoleArn: !GetAtt IoUserSdkApiRole.Arn256 ContainerDefinitions:257 - Name: IoUserSdkApi258 LogConfiguration:259 LogDriver: awslogs260 Options:261 awslogs-group: !Ref IoUserSdkApiLogGroup262 awslogs-region: !Ref AWS::Region263 awslogs-stream-prefix: IoUserSdkApiService264 Image:265 !Sub ${AWS::AccountId}.dkr.ecr.${AWS::Region}.${AWS::URLSuffix}/{{IoUserApiEcrRepositoryId}}:{{container_name}}266 PortMappings:267 - ContainerPort: {{cluster_service_port}}268269 IoUserSdkApiService:270 Type: AWS::ECS::Service271 Properties:272 Cluster: {{IoEcsClusterId}}273 LaunchType: {{ecs_launch_type}}274 DesiredCount: {{ecs_container_multiplier}}275 DeploymentConfiguration:276 MaximumPercent: 200277 MinimumHealthyPercent: 100278 NetworkConfiguration:279 AwsvpcConfiguration:280 SecurityGroups:281 - {{IoContainerSecurityGroup}}282 Subnets:283 - {{PrivateSubnetA}}284 - {{PrivateSubnetB}}285 {% if PrivateSubnetC is defined %}286 - {{PrivateSubnetC}}287 {% endif %}288 TaskDefinition: !Ref IoUserSdkApiTaskDefinition289 LoadBalancers:290 - ContainerName: IoUserSdkApi291 ContainerPort: {{cluster_service_port}}292 TargetGroupArn: !Ref IoUserSdkApiLoadBalancerTargetGroup293294 IoUserSdkApiLoadBalancerTargetGroup:295 Type: AWS::ElasticLoadBalancingV2::TargetGroup296 Properties:297 HealthCheckIntervalSeconds: 6298 HealthCheckPath: /healthcheck299 HealthCheckProtocol: HTTP300 HealthCheckPort: '{{cluster_service_port}}'301 HealthCheckTimeoutSeconds: 5302 HealthyThresholdCount: 2303 TargetType: ip304 TargetGroupAttributes:305 - Key: deregistration_delay.timeout_seconds306 Value: '30'307 Port: {{cluster_service_port}}308 Protocol: HTTP309 UnhealthyThresholdCount: 2310 VpcId: {{VPC}}311312 IoUserSdkApiLoadBalancerListenerRule:313 Type: AWS::ElasticLoadBalancingV2::ListenerRule314 Properties:315 Actions:316 - TargetGroupArn: !Ref IoUserSdkApiLoadBalancerTargetGroup317 Type: forward318 Conditions:319 - Field: path-pattern320 Values:321 - /users322 - /users/*323 ListenerArn: {{IoSharedSdkApiLoadBalancerListenerArn}}324 Priority: 1325326{% if 'prd' not in acc %}327 AutoScalingTarget:328 Type: AWS::ApplicationAutoScaling::ScalableTarget329 Properties:330 MinCapacity: {{ecs_container_multiplier}}331 MaxCapacity: {{ecs_container_multiplier*2}}332 ResourceId: !Sub service/{{IoEcsClusterId}}/${IoUserSdkApiService.Name}333 ScalableDimension: ecs:service:DesiredCount334 ServiceNamespace: ecs335 RoleARN: !GetAtt IoUserSdkApiRole.Arn336 ScheduledActions:337 - ScalableTargetAction:338 MinCapacity: 0339 MaxCapacity: 0340 Schedule: {{ecs_scale_in_schedule|default(omit)}}341 ScheduledActionName: ScaleIn342 - ScalableTargetAction:343 MinCapacity: {{ecs_container_multiplier}}344 MaxCapacity: {{ecs_container_multiplier*2}}345 Schedule: {{ecs_scale_out_schedule|default(omit)}}346 ScheduledActionName: ScaleOut347{% endif %}348
Lines 7-122 define an api gateway with both Lambda and Fargate powering different endpoints:
/sdk endpoints
- API key authorization via sigv4
- ECS Fargate cluster backend
/admin endpoints
- Cognito authorization via a Lambda authorizer function
- Lambda function backend
Lines 124-131 attach our api gateway to a shared domain name for this environment under the /users path
Lines 133-171 create a role for the admin api function, with limited access to the specific resources it needs.
Lines 173-182 create the /admin backend function
Lines 184-189 grants access to api gateway to invoke the /admin lambda function
Lines 191-244 create a role for the /sdk fargate task
Lines 246-324 create a fargate task definition, service and load balancer rule and attaches them to the shared ecs cluster and load balancer for the environment
Lines 326-347 create an autoscaling schedule (individual schedules are defined in Ansible inventory) to shut down non-prod fargate services outside of business hours.
Conclusion
While we are still on the journey to full CD, we are very happy with how the platform has been performing and with how easily non DevOps developers have taken to the codebase. In most cases developers have been able to create and modify APIs and pipelines with little to no assistance. It's hard to understate the velocity boost this gives our team and the productivity bump that comes from empowering developers to better understand the infrastructure that their code is running on.
Hopefully if you are still reading now, you were able to find some value in this overview of our experiences. If you are looking for more details on any specific parts of our stack, or just want nerd out about tooling, hit me up on the LinkedIn link at the top of the post.